
Solving the data anonymization problem in Postgres
We're partnering with Neon to help companies of all sizes easily anonymize their sensitive data in Postgres for a better developer experience
May 28th, 2024

We recently shipped Subsetting with Referential Integrity in Neosync and we wanted to give an overview of how we built referential integrity into subsetting. We expose the ability to use referential integrity in your Subsetting page through a simple switch component but under the covers there is a lot of logic and code to make this happen.

In this blog, we're going to walk through how we implemented referential integrity into our Subsetting feature. If you like graph problems, then this blog is for you.
Subsetting is a technique that developers can use to shrink their database by taking a fraction of the data in their source database and moving it to their destination database. There are two main use cases for subsetting.
The first is debugging errors. Say that a customers is experiencing a bug and you want to reproduce it. Instead of wholesale copying down the production database, you should only take the data that you need (and also anonymize any sensitive data). Subsetting would allow you to subset your production data by that customer id and make it easier to reproduce due to just having less data overall.
The second use-case is for reducing the size of the data that you're copying across databases. If your production database is 5TB and you want to do some work locally, it's unlikely that your local database will be able to hold that much data. Subsetting is a great way to "shrink" your production database to one that is usable locally.
The requirements for referential integrity in subsetting are actually pretty straightforward. The user story is: As a user, I want to be able to subset my database using one or WHERE clauses and get a dataset back that contains all of the relevant and referred data.
Functionally this means that we need to understand the relationships between tables in order to select and filter the data to just the rows that we care about while accounting for primary keys, foreign keys and other dependencies.
Whenever we design a new feature, we try to follow our design philosophy: flexibility without complexity. This means designing a feature that is super simple to use but is also really flexible and powerful. Here is the interface to the subsetting page:
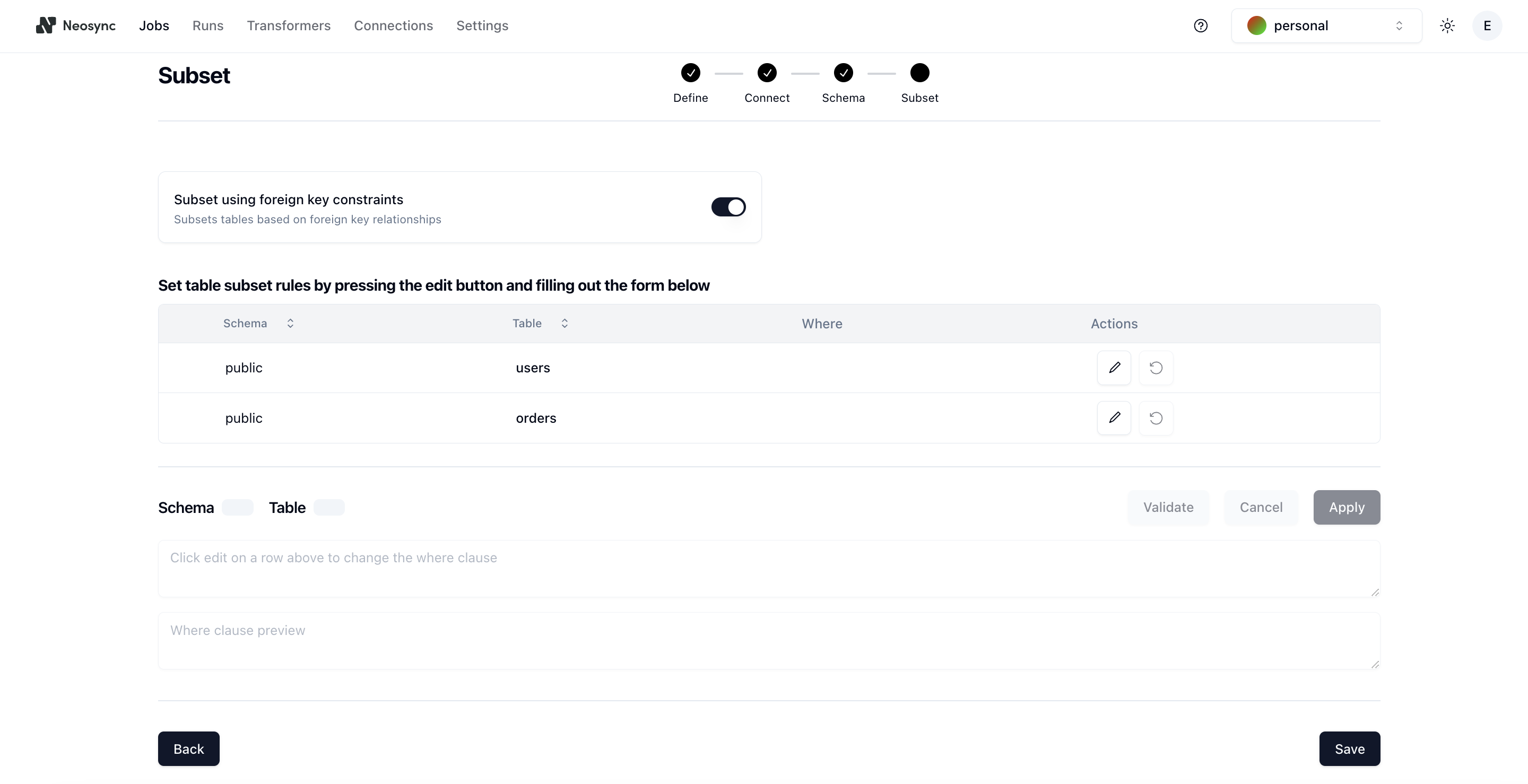
It's broken down into 3 sections. The first is the switch at the top that allows users to toggle referential integrity on or off. The second section lists the schemas and tables to the user and allows them to take an action on those tables. The last section is the query validation section that users can use to enter in a query for the subset and validate that it will work.
The flexibility part comes into play in the second and third sections where the user can add in multiple subsetting queries per table or across tables and validate those queries against the database. This is quite unique to the Neosync platform and we haven't seen anyone else take this approach to subsetting. The lack of complexity is manifested in a single switch that the user has to select to enable referential integrity.
We can broadly break down referential integrity into two types: linear dependencies and circular dependencies.
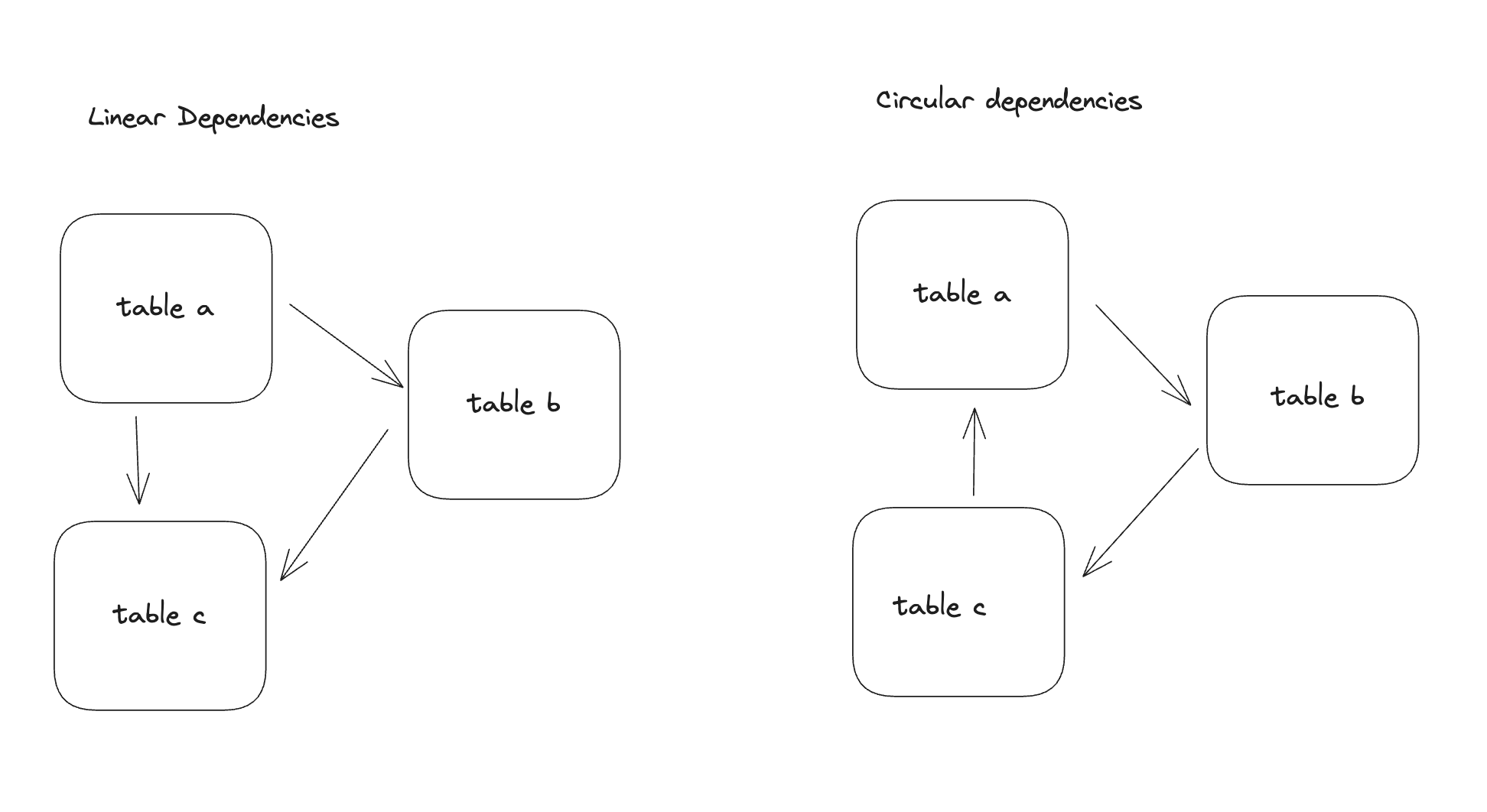
In the following sections, we'll break both of these types down and explain the logic behind how we implemented this.
Linear dependencies move in one direction and do not form an enclosed loop. In classic computer science language, this would be called a Directed Acyclic Graph (DAG). It's Acyclic because there is no loop formed. In the example above, table a points to table b and table c but no closed loop is formed. This is pretty common in most databases where you have a table that references another table with one or more foreign keys.
In Neosync, a user would provide us one or multiple SQL queries that they want to use to filter the table by. We can think of this as our entrypoint since this is where we start from. The general approach is:
SELECT and JOIN queries in order to accurately represent data structureFor a few tables, this is pretty straightforward, but most companies may many tables. Some of our customers have hundreds of tables with very complicated dependencies so this can get pretty complex pretty quickly. The end result can be many nested joins but the general approach is consistent.
Once we have the data that we need, we need to insert that data into another database because Neosync is used to sync data across databases. The insert also gets pretty interesting because there is an order. Remember that this is a DAG and DAGs have a direction.
When we want to insert the data, we follow this general strategy:
If we were to insert the data in any order, our foreign keys would complain that the reference doesn't exist. Which makes sense. We can't have a foreign key reference data if the reference data doesn't exist!
The other wrinkle to mention here is if the user wants to transform their primary keys or data that has a foreign key. Think of a foreign key on an email address. If you want to anonymize that data, then you need to track the transformed output from the input in order to insert the correct value. But that's for another blog post for another day.
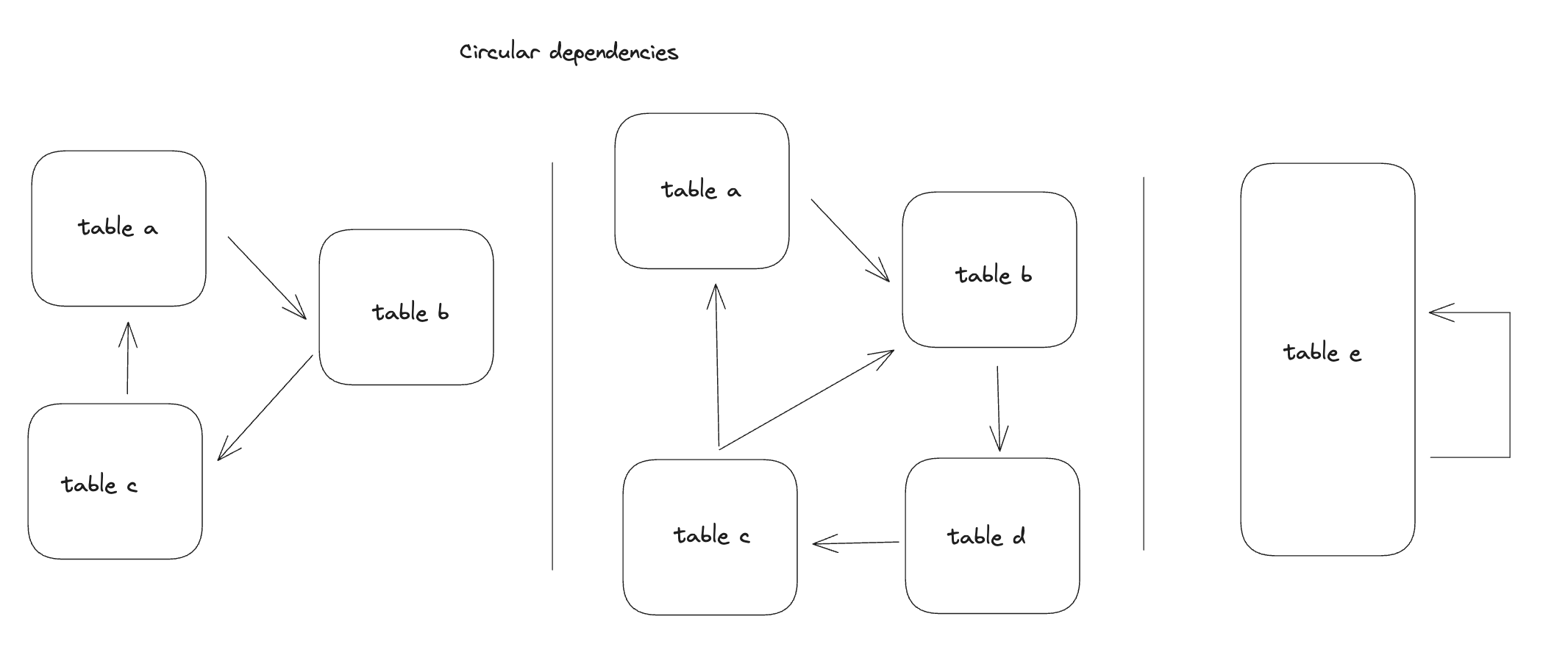
Circular dependencies form one or more closed loops within a number of tables or within a table as shown in the image above. Circular dependencies are more complicated than linear dependencies and require that we do more work (and use recursion!) to be able to handle them appropriately.
Similar to the linear dependencies, a user would provide us with one or multiple SQL queries that they want to use to filter the table by. This would serve as our entrypoint.
SELECT and JOIN and UNION queries in order to accurately represent data structure. In cases where there is a circular dependency, use Common Table Expressions (CTE) recursive functions to accurately model data relationships.The added layer of complexity here is in using recursive functions to manage the circular nature of these relationships. And just as in the linear dependencies, we have to be careful to insert the data in the correct order (direction) otherwise our foreign keys will panic about missing references.
Implementing referential integrity in subsetting was a fun challenge to take on. As a team, we spent a lot of time drawing boxes and arrows on a whiteboard and thinking through the edge cases. We also implemented this for Mysql and Postgres which added an extra layer of difficult since Mysql and Postgres have different syntax and functionality.
If you want to check out the code that we used to implement this in GO, check out this file which has most of the base functions.
We've also made Neosync free to try.
Check it out and let us know your thoughts.
We're partnering with Neon to help companies of all sizes easily anonymize their sensitive data in Postgres for a better developer experience
May 28th, 2024

A guide to using AI to generate synthetic data for your database and application using any LLM that is available at an endpoint.
May 21st, 2024

